Imagine calling a company's customer service line, only to find they have no record of your recent online purchase. Or picture receiving email promotions for products you've already bought. Perhaps you've experienced the frustration of loyalty points that don't sync across different platforms. These disjointed experiences are what happen when businesses lack a unified view of their customers across various touchpoints. Enter identity resolution - the art and science of connecting disparate data points to form a coherent picture of individual customers. Making sense of this data to deliver personalized experiences and improve marketing is where identity resolution comes in.
This article aims to explain what identity resolution is, why it's important, how it works, the challenges involved, and practical applications. By the end, you’ll understand how to effectively implement identity resolution in your business.
What is Identity Resolution?
At its core, identity resolution is all about connecting the dots. It's a process that businesses use to link various pieces of information about a customer to create a single, comprehensive profile. Have you ever wondered how a company seems to know just what you need, when you need it? That's identity resolution at work.
In a world where we interact with brands through multiple channels — think emails, social media, websites, and in-store visits — identity resolution helps businesses paint a full picture of who their customers are. This isn’t just about knowing your name and your favorite color. It's about understanding your habits and preferences across different platforms and using this insight to deliver a unified personalized experience.
Now imagine browsing online for a new laptop and later receiving an email with a special offer on that exact model. Or think about a customer service agent knowing your purchase history as soon as you call, ready to help with your specific issue. These aren’t coincidences—they’re the result of identity resolution systems working behind the scenes.
Why is Identity Resolution Important?
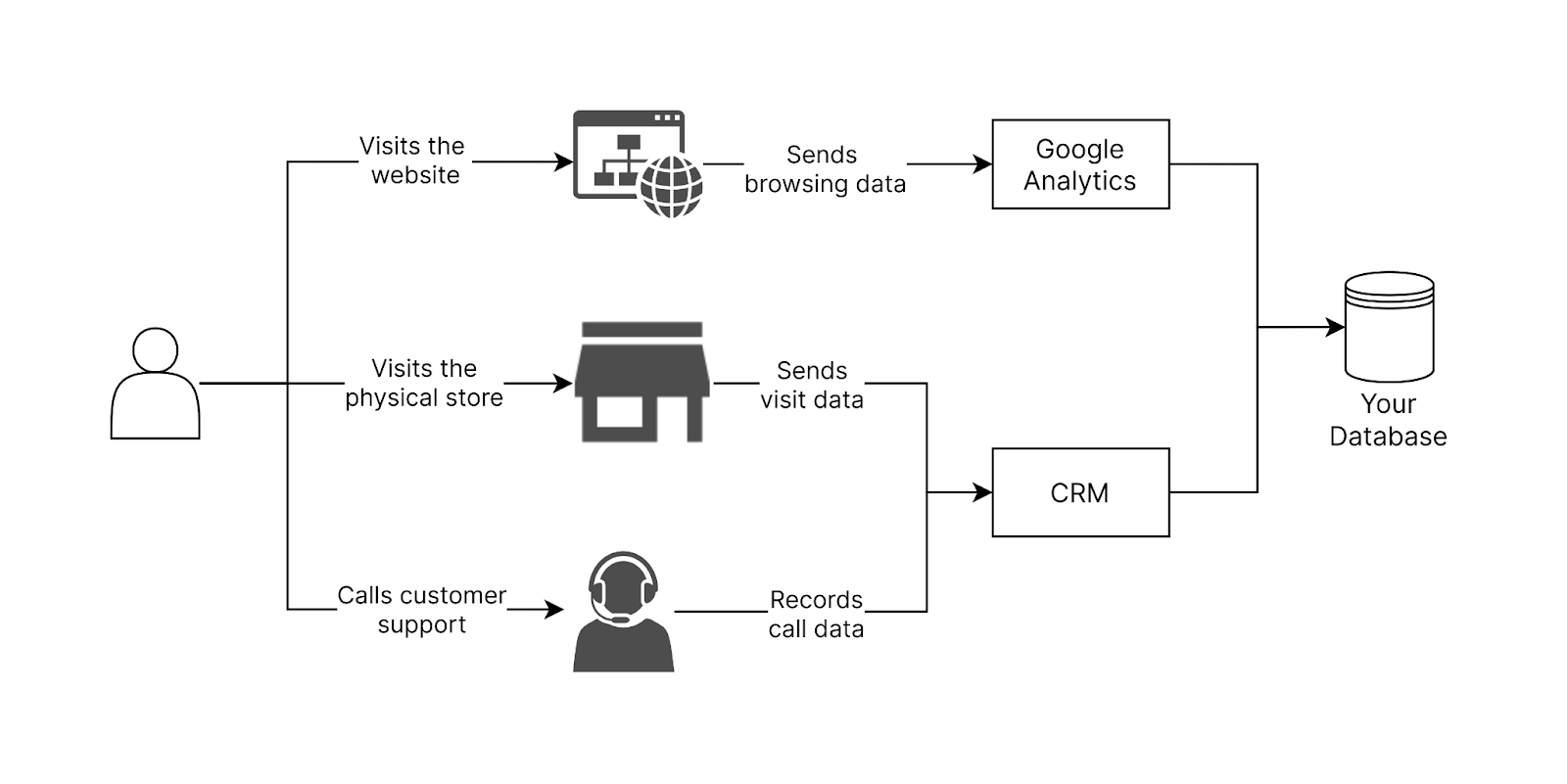
As people interact with businesses through multiple channels like websites, apps, physical stores and call centers, it becomes increasingly difficult to understand what each individual customer is doing. This makes it almost impossible to analyze the onboarding process, the interactions that are significant to achieving certain goals (purchase a service, upgrade to a higher tier, engage with loyalty programs) and the factors that eventually led to churn.
What caused a customer to churn? Was it a bad experience with the support call center? Was it because of unmet expectations created in the sales process? Was it because of a missed delivery?
What convinced the customer to finally engage with the online store platform? Were they influenced by a visit to the physical store where they discussed with the sales agents?
What made a user decide to create an account in the app? Was it because they spent the previous few days browsing anonymously on the website or because of the current ongoing advertisement campaign?
These are all questions that can be answered by having a good identity resolution system in place. It gives you a 360 view of the journey your customers take across multiple touch points. This is particularly important, since a key interaction from one touch point can influence their behavior in another.
Additionally, identity resolution can also help businesses offer personalized experiences. Consider a beauty product company that operates an online platform, publishes beauty-related articles, and has several physical stores. Suppose an existing customer visits one of their stores. The sales agent can check their interactions with the company’s website and see that they recently read many of their articles on dry skin. Using this information, the sales agent recommends specific moisturizer products, which the customer then purchases.
Who Needs Identity Resolution?
Identity resolution is crucial for a wide range of businesses and is especially beneficial for certain departments within those organizations.
Key Industries
Retail and E-commerce: Retailers and e-commerce platforms benefit from identity resolution by gaining a holistic view of customer interactions across various channels. This enables personalized shopping experiences, tailored marketing campaigns, and efficient inventory management. For instance, by linking online browsing behavior with in-store purchases, retailers can offer more relevant product recommendations and promotions.
Financial Services: Identity resolution helps banks and other financial institutions prevent fraud by linking disparate pieces of customer data to spot inconsistencies and unusual activities. It also plays a crucial role in personalizing banking services, enhancing customer satisfaction and loyalty by offering tailored financial products.
Healthcare: Accuracy is critical in healthcare. Identity resolution helps healthcare providers consolidate patient records from various sources into a single, comprehensive view. This complete picture supports better diagnosis, treatment planning, and patient care, all while ensuring compliance with strict privacy regulations.
Departments and Stakeholders That Benefit the Most
Chief Marketing Officers (CMOs): CMOs benefit immensely from identity resolution as it enables precise targeting and personalization in marketing campaigns. By understanding customer behaviors and preferences, CMOs can craft strategies that not only attract customers but also convert their interest into sales, enhancing both engagement and conversion rates.
Customer Service Teams: The key to offering quality support to customers is to understand the context and the specific needs. Customer service departments make use of identity resolution to do just that: form a better picture of each individual client. By having a comprehensive view of their past interactions with the business, it allows the customer service agents to resolve issues more quickly and provide personalized support.
Sales Departments: Sales teams use identity resolution to fine-tune their sales pitches. Knowing a customer’s previous interactions and preferences helps them identify and capitalize on upsell and cross-sell opportunities, which increases sales performance and fosters long-term relationships with customers.
How to Perform Identity Resolution?
Performing identity resolution boils down to a few key steps:
Preparations
Before any identity resolution takes place, it’s necessary to set up the right systems. Depending on the business, this can include implementing Google Analytics or single sign-on on your websites and apps along with the right tracking, choosing the right CRM software for recording customer interactions and deciding on what customer data is relevant to your business.
Collecting the Data
After ensuring that all the prerequisites are taken care of, the data should be brought into an easy-to-access environment (such as a data warehouse) where it can be processed and joined together. This involves setting up various ETL (extract, transform, load) pipelines, connecting to various APIs and configuring integrations with the necessary platforms, such as the CRM.
Cleaning the Data
In general, different platforms and systems will have different ways of storing the data. For example, whereas Google Analytics might store the phone number in the format (123) 456-7890, the CRM might store the phone number in the format 123-456-7890. Similarly, in the case of touch points where the customers have to fill in their data manually (for example when manually signing up for the newsletter), there is the possibility of making mistakes - think of writing the country in the city field and vice-versa.
Cleaning the data is an essential part of the process, which ensures a unified “language” across all the records. It
Matching the Data
This step is the core part of the identity resolution process. It involves figuring out the right way to join the data from multiple touch points to identify the same customer. Data matching can be done using multiple methods, each one having its own set of advantages and disadvantages.
Deterministic Methods
Let’s first talk about deterministic methods. These rely on identifiers like emails, phone numbers and other bits of customer information to match the data exactly as is.
If you find the same name across multiple records, you can use it to identify the same customer across multiple touch points. However, while names are commonly used, they aren’t unique enough on their own. Therefore, combining names with unique identifiers like email addresses or IP addresses can improve the accuracy of these matches significantly.
Deterministic methods rely heavily on data quality. Any inconsistencies across datasets (like differently formatted phone numbers) or spelling mistakes (Jon Doe vs John Doe) drops the accuracy significantly.
If the preliminary data preparation and tracking methods are properly implemented, deterministic methods become highly effective and straightforward to execute. For instance, the right tracking ensures that each user gets assigned a consistent and distinct ID across different touch points, which can be used to easily join the records.
Real life, however, is never this straightforward.
Even with the best data preparation and validation processes in place, mistakes and inconsistencies still slip through. Be it due to human error or the nature of the data collection method, there are instances where it is impossible to match the data exactly.
- What if a customer made a spelling mistake when filling in a contact form?
- What if the social media platform only gives you access to the customer’s username, age bracket, country and nothing else?
- What if due to privacy reasons, a platform only gives you partially obfuscated data—“John D.” instead of “John Doe” and “je@example.com” instead of “john_doe@example.com”?
In all of these situations, deterministic methods are not enough to resolve the identity of a customer across different touch points.
Probabilistic Methods
Enter the world of probabilistic methods. As the name suggests, these methods infer matches based on patterns and probabilities, not just exact data matches. They employ more advanced algorithms to decide if two records belong to the same individual, even if they are not exactly the same. This is particularly useful in scenarios where data may be incomplete, obfuscated, or slightly inaccurate.
Dealing with inconsistencies and risk management
Suppose we want to match the CRM customers with the social media customers using the email, which is a common identifier found in both datasets. The social media platform gives partially obfuscated data, which cannot be joined with the CRM data directly, through deterministic methods.
Employing a probabilistic algorithm that finds matches based on patterns indicates a 70% chance that “jo*e@example.com” is the same as “john_doe@example.com”*. ***Would a 70% probability be sufficient for you to accept it as a match? Consider this:
- Being too permissive (having a low threshold) increases the probability of false positives—different customers being matched with one another.
- Being too strict (having a high threshold) increases the probability of false negatives—missing matching records from the same customer.
Therefore, part of implementing probabilistic identity resolution processes within your business involves deciding on what threshold works best for your needs and strategy.
Think about this—if you are working within the health sector, trying to consolidate patient records, there is no room for error (false positives), so having a high threshold is essential. Meanwhile, in a marketing context where the goal is to increase the customer base, you might choose a lower threshold to capture a wider range of potential matches at the expense of accuracy.
Dealing with the lack of common unique identifiers
So far, we have explored the cases where we have a well-defined set of identifiers like email, name, phone number across all touch points, and we've discussed solutions to handle inconsistencies. However, what happens when datasets, such as CRM and Google Analytics, lack any common unique identifiers?
For instance, if the only overlapping data between two touch points are general demographic details like country, city, or age bracket—attributes shared by many users—identifying unique customers becomes much more complex. In such cases, how should we proceed?
Again, probabilistic matching is the way to go. By using the available demographical data, we can statistically infer matching records.
Imagine this: there are multiple people called John Doe in the world. However, how many of them live in the state of Texas, are in the 35-40 age bracket, have an iPhone 12 mini and drive a yellow Subaru? Even though each attribute is very general and shared by many people, this unique combination of them might be enough to identify our John Doe with a high probability.
If we see two users having many common attributes (like in the example above), we can consider them the same, due to how unlikely it would be for two distinct people to share all of them.
Deterministic vs Probabilistic methods—quick overview
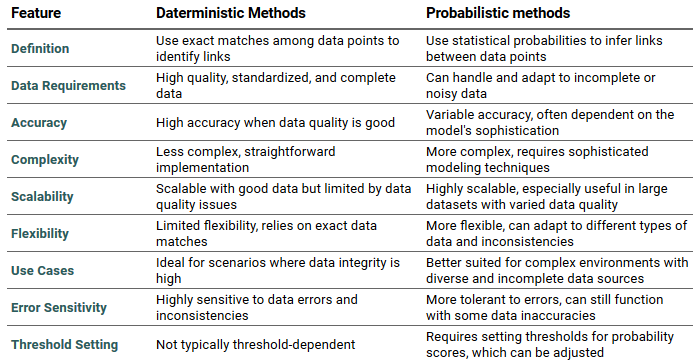
In most real-life scenarios, identity resolution will employ both methods.
What are the Main Challenges?
On paper, identity resolution seems straightforward: gather data, match it, deliver personalized experiences. However, implementing a robust identity resolution system is a complex task that can take from a few months to more than a year. Most of that time is spent overcoming the various challenges that arise during the process.
Architecture Limitations
In most organizations, identity resolution comes at a later stage in the development of the data analytics department, after the architecture is already established. At this stage there are usually countless ETL processes and data collection methods in place, many critical dashboards using the current setup and many cross-organizational systems using the data.
This means that when the identity resolution project begins, there is usually little flexibility to change the current way of working, which took years to build. This usually limits the development team to the already-collected data and the existing systems, which might not be ideal or even usable for identity resolution.
- How do you ensure that the data collection stage was properly handled and supports the identity resolution process?
- Is there anything else needed?
- What does it take to update the existing setup without causing disruption within the organization?
Ideally, organizations that benefit heavily from having an identity resolution system, should develop their data analytics architecture with this goal in mind from the get-go to avoid disruptions and higher development costs down the line.
Updating Customer Information
One of the ongoing challenges in identity resolution is accounting for changes in customers' personal information over time, such as updates to phone numbers, addresses, or even names due to various life events like marriage or relocation. This dynamic nature of personal data introduces a level of complexity to maintaining accurate and up-to-date customer profiles. Individuals evolve and so does their digital footprint, requiring a system that can not only track these changes efficiently but also adjust the connected data points accordingly.
Without a mechanism to update these changes, businesses risk basing their strategic decisions on outdated information, leading to inefficient marketing efforts and poor customer experiences.
Identity Resolution Providers and Google Cloud Platform
Using third-party identity resolution service providers
In certain situations where an organization doesn’t have the necessary resources to implement and manage an identity resolution system or are looking for a specific solution that requires expert knowledge in the field, they can leverage the power of identity providers—companies specialized in advanced matching algorithms. These providers offer managed services that incorporate complex data processing and matching techniques which can be applied on your data.
Each identity provider has their own pricing system, which means that you will have to contact them and discuss these aspects individually.
Depending on how your data is stored, there are multiple ways to integrate the services of identity providers. One way to do it is by leveraging a GCP (Google Cloud Platform) framework which allows identity providers to connect to your BigQuery data directly and apply their identity resolution techniques in-database. This reduces the cost significantly by removing the need to move the data between entities, while also covering any security and legal concerns that might arise in transferring the data.
How it works
- Choose an Identity Provider: Begin by partnering with an identity provider (such as LiveRamp, which is trusted by Google). The provider will have the necessary tools and algorithms to perform the matching.
- Set Up Datasets: Configure the data that will be used in the matching process.
- Grant Access: Provide the identity provider's service account with the necessary permissions to read from the input dataset and write to the output dataset. This ensures that the provider can access your data securely and efficiently.
- Invoke the Matching Process: Use a remote function call to trigger the identity resolution process. This call passes your data to the identity provider’s system, where it is matched against their identity graph.
- Receive Matched Data: The identity provider processes your data and writes the matched results back to your output dataset in BigQuery. This enables you to work with a unified set of records that accurately reflects your customer base.
Please refer to the BigQuery entity resolution documentation for more information on the process.
Using third-party data
In certain cases, companies have the option to enrich their customer profiles with third-party data. This data can be purchased from specialized vendors that collect, consolidate and ensure up-to-date data on millions of email addresses, phone numbers and more. The data is collected from diverse channels such as online surveys, loan applications, voter registrations, property records, and consumer finance records. Depending on the vendor and the identity resolution algorithms they employ, each record can be very detailed, including information from simple demographic details, such as age, gender and income, to household identifiers which can be used to determine the emails belonging to people who live together.
Example use case
Consider an e-commerce company that runs an online store. The organization stores its users by email, which is the unique account identifier. By default, each account has a very limited number of attributes, such as email address, phone number and city, which were filled in manually at sign up. By themselves, these attributes cannot be used for personalized offers or advanced analyses, so the company decides to enrich their user profiles by purchasing third-party email data from a vendor.
Despite the vendor having data on millions of emails, the e-commerce company’s customer base is only a fraction of the amount. Moreover, the vendor might not have data on all the emails the company has.
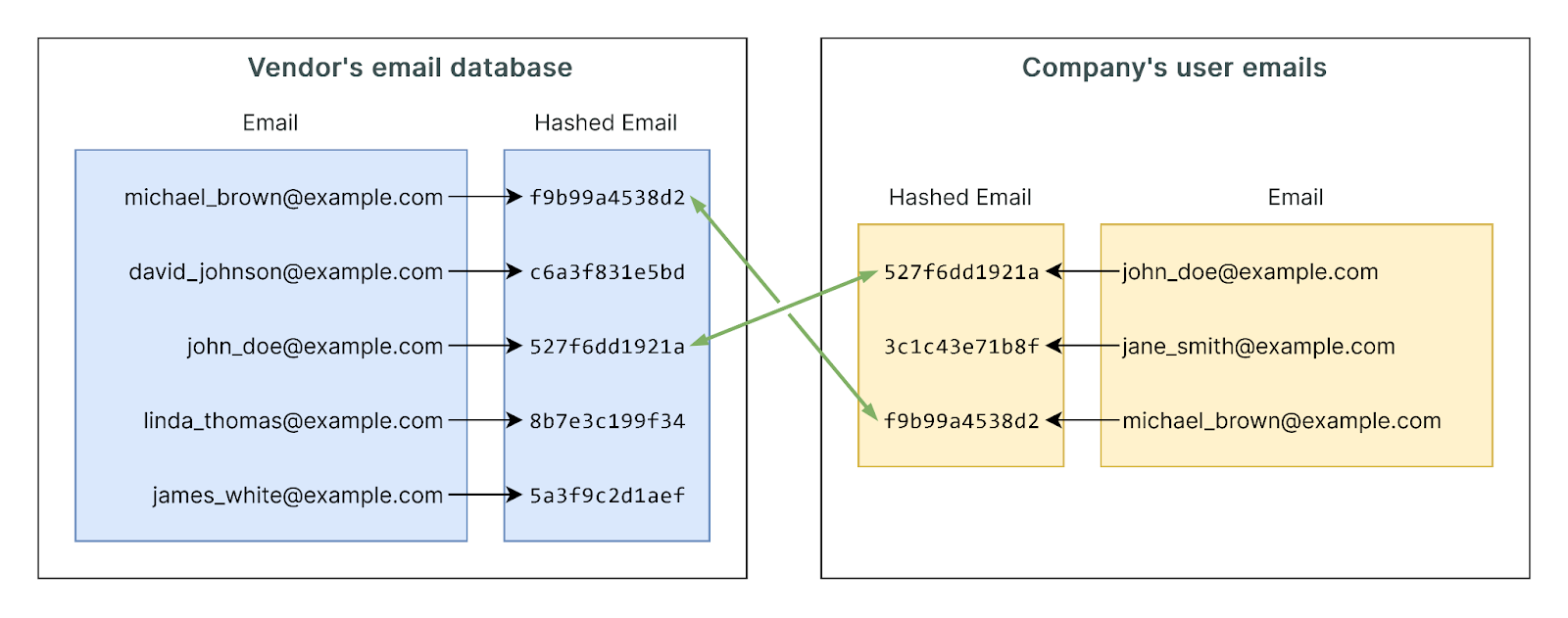
So how do the vendor and the company identify the common emails (owned by both parties) without sharing their entire private databases?
The answer is hash matching. Hash matching is a method where both parties convert email addresses into hashed values using the same algorithm (e.g., SHA-256 or MD5). These hashed values are then compared to find matches without revealing the actual emails.
- Generate Hashes: Both the e-commerce company and the data vendor independently hash their email lists using the same hashing algorithm.
- Exchange Hashes: The hashed email lists are exchanged between the two parties without revealing the actual email addresses.
- Compare Hashes: Both parties compare the hashed values to find matches. Since hashing is a one-way function, the original emails cannot be derived from the hashes, ensuring privacy.
- Data Enrichment: For the matched hashes, the vendor provides enriched data corresponding to those emails, which the e-commerce company can then integrate into their CRM system.
Notice that neither party sees the emails of the other party. They only see the hashed versions, which is what they are comparing.
By purchasing the common emails and enriching their user profiles, the e-commerce company can offer personalized offers to their customers. For example, it is possible to target a couple living in the same household individually, recommending specific gifts for each other.
Example Use Case: Telecommunications Company with Multiple Brands
Imagine a telecommunications company that manages two brands, each having its own digital presence, website and application. The brands are complementary to each other, so there are multiple users interacting with both of them. The challenge consists in building a 360-degree view of the customers, tracking their journey across all the digital properties of the company, while also correlating them with the CRM database, which stores information about their subscription type, extra options and other personal information necessary for advanced analyses.
To prepare for this project, the initial stage is essential. In this case, it consists of implementing a single sign-on system as well as adding Google Analytics to all the digital properties. The single sign-on system allows users to use a single set of credentials to log in across all of their apps and websites. This process assigns a unique identifier called SSOID (Single Sign-On ID) to each account, which is captured by Google Analytics and assigned to each user. Later, using the SSOID, which is the common identifier, the company can track the same user across multiple touch points.
Based on the available data, the data engineers create a table called “anon_associations”, which stores the correlation between SSOIDs and user_pseudo_ids (which are assigned automatically by Google Analytics to each user and event).
The CRM data stores customer attributes (phone numbers, email addresses, …), as well as customer support interactions. This data needs to be matched with the Google Analytics events.
By tracing the common identifiers between the tables, using the Anon_associations table, the customer data can be matched through deterministic methods.
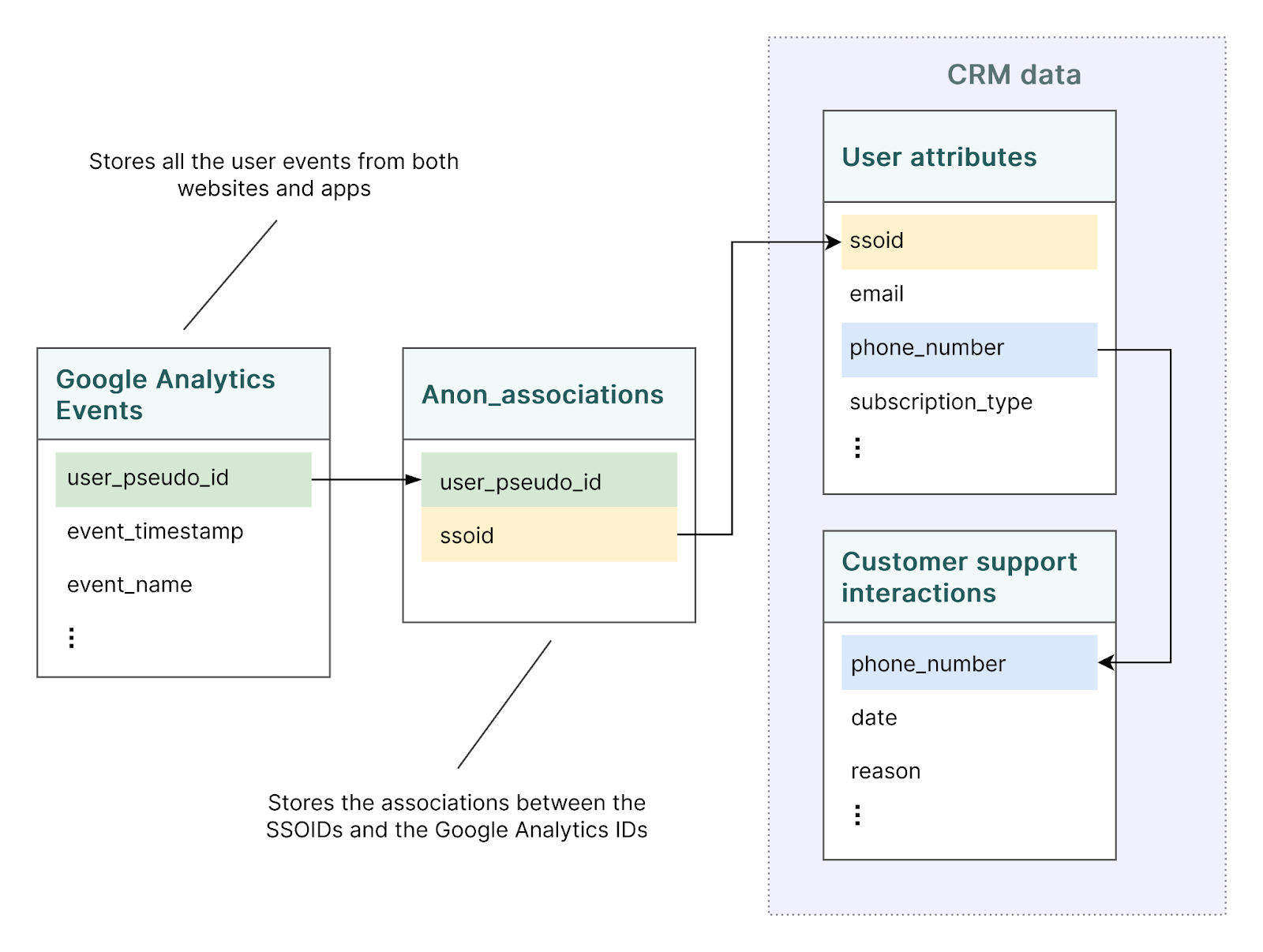
This setup allows the organization to answer questions like:
- Which brand interactions lead to higher customer lifetime value across both services?
- How do offline support interactions influence online engagement and subscription upgrades?
- What cross-selling opportunities exist based on usage patterns across both brands?
- Which customer segments are most likely to churn, considering behavior across all touchpoints?
- How does the customer journey differ between high-value and low-value customers across brands?
- What is the impact of marketing campaigns on overall customer engagement and revenue?
- Which features or services drive the most loyalty when users interact with both brands?
- How can personalized offers be optimized based on unified customer profiles and preferences?
- What are the most effective upselling strategies considering both online and offline interactions?
- How does customer satisfaction correlate with usage patterns across digital properties and brands?
More advanced identity resolution methods: mouse movement, typing patterns
As digital interactions become more and more prevalent and nuanced, traditional methods of identifying users can be enriched with more advanced ones, such as mouse movement and typing patterns analysis.
Each person has a unique way of interacting with their devices, analogous to a fingerprint, which can be used to identity users. These methods are already implemented in security related systems, such as CAPTCHA, to distinguish real people from bots, or to trigger an additional authentication step when the movement patterns are not typical of a given user.
How It Works
1. Mouse movement analysis
Mouse movement analysis involves tracking the way a user moves their mouse across the screen. This includes patterns such as speed, pauses, clicks, and the trajectory of the cursor. Each person has a distinctive way of interacting with their computer that can be as unique as a fingerprint. By capturing and analyzing these patterns, systems can develop a behavioral profile for each user.
2. Typing patterns analysis
Typing pattern analysis (also known as keystroke dynamics), examines the rhythm and speed of a person's typing. This includes metrics like the time taken to press and release each key, the duration between keystrokes, and typing speed variations. Much like mouse movements, typing patterns are highly individualistic and can serve as a reliable biometric identifier.
Example
A system can monitor how an anonymous (logged off) user navigates your company’s website by tracking the mouse movement and typing pattern variables to create a user profile. Later, when the same user logs in and uses the website, the movement and typing patterns can be matched to the anonymous user and attribute all the previous interactions.
Implementation and Considerations
While these advanced identification techniques can be powerful tools, they are significantly more complex to implement and require highly advanced technical skills, which might not be readily available within the business.
Furthermore, creating a user profile based on a continuous stream of biometric data can be a resource-intensive process, requiring an extensive architecture that supports it. Using cloud solutions, such as GCP (Google Cloud Platform) or AWS (Amazon Web Services) can overcome this limitation by providing scalable and flexible infrastructure solutions. These platforms offer the computational power and storage capabilities needed to handle large volumes of data.
Conclusion
In conclusion, in today’s world, where customers have increasingly nuanced interactions with businesses across multiple touch points, identity resolution becomes essential by providing the necessary mechanism to understand the user base. Without it, forming a 360-degree view of your customers would be impossible, as each touch point would be analyzed individually, missing the immense potential of integrated data.
We have discussed the implementation of identity resolution, emphasizing the importance of initial preparations for smooth development and avoiding future disruptions. We also covered the data cleaning stage, essential for accurate matching, and explored various forms of identity resolution—from straightforward deterministic methods requiring high-quality data to more adaptable probabilistic methods that handle noisy and incomplete data.
However, implementing identity resolution comes with its challenges. Businesses must navigate architectural limitations, data inconsistencies, and the dynamic nature of personal information. Despite these obstacles, the future of identity resolution looks promising with advancements in machine learning and biometric analysis, offering even more precise and insightful customer profiles.
As technology evolves, so too will the methods for identity resolution, making it crucial for businesses to stay informed and adaptable. We encourage readers to continue educating themselves on this topic and consider how these advancements can be integrated into their own organizations to enhance customer understanding and engagement.