Consider a familiar mid-market setup.
There is a senior IT leader responsible for infrastructure, security, vendors, data requests, and whatever the business calls "digital transformation" this quarter. There is a sysadmin who keeps the systems running. There is an analyst who knows SQL and can build useful reports but is not a software engineer. There may be one more person helping across support, data, and operations.
That is the team. Small, capable, already stretched. And someone in leadership has just asked them to "look into AI agents."
If that sounds like your company, this article is for you. Not for Google's engineering org. Not for a fintech startup with 40 developers. For the companies that need useful automation, but have to live with the system after the demo is over.
The wrong question is "which AI agent framework is best?" The right question is: what can we actually deploy, maintain, and trust with the team and budget we have?
What AI Agent Frameworks Actually Do (In Plain Language)
Before we compare anything, let's make sure we're talking about the same thing. The AI industry has done a spectacular job of making this confusing, so here's the picture stripped down to what matters.
An AI model is the brain. It's what OpenAI, Anthropic (Claude), Google (Gemini), or open-source projects like Llama and Mistral provide. You send it a question, it sends back an answer. That's the core capability.
An AI agent is a model that can also take actions. Instead of just answering "you should check the inventory system," an agent can actually go check the inventory system, pull the number, compare it against the reorder threshold, and draft a purchase order for you to approve. The difference is agency: the ability to use tools, access data, make decisions in sequence, and loop back when something doesn't work.
An AI agent framework is the plumbing that makes that possible. It handles the boring but critical parts: what tools can the agent use? In what order does it do things? What happens when it fails halfway through? Where does it store the state of a task that takes longer than one API call? How does a human approve or reject what the agent wants to do?
An orchestration protocol is the standard that lets agents connect to external tools and to each other. MCP (Model Context Protocol) is the emerging standard for connecting agents to tools and data sources. A2A (Agent-to-Agent) is the emerging standard for agents talking to other agents.
For a lean IT team, the framework and protocol choices matter more than the model choice. Models are interchangeable: you can swap OpenAI for Claude or Gemini relatively easily. But the framework you build on determines how much engineering effort you need, how much you can trust the system, and how hard it will be to maintain after launch.
When You Actually Need an AI Agent (And When You Don't)
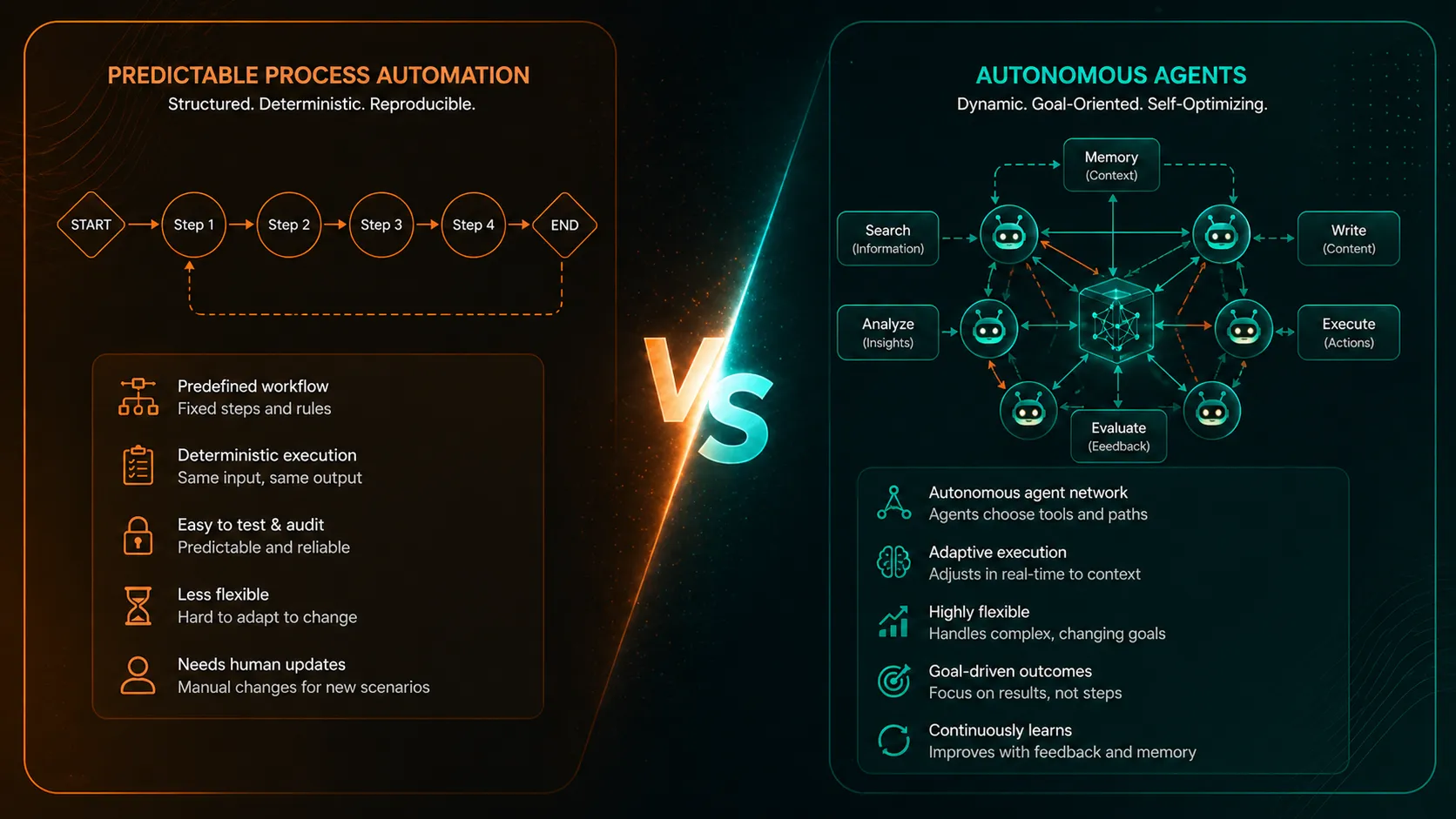
This is the most important section of this article, because it will save you from the most expensive mistake in the AI agent space: building an agent when you should have built a workflow.
Here's the distinction that matters:
A deterministic workflow does the same thing every time, in the same order. If a new sales lead comes in, create a CRM record, send a welcome email, notify the account manager, schedule a follow-up task. That's automation. You don't need an AI agent for that. You need Zapier, Make, n8n, or a simple script. It will be cheaper, more reliable, and easier for your sysadmin to maintain.
An AI agent makes sense when the task requires judgment, variability, or working with unstructured information. If a customer sends an email asking about a product, and the agent needs to understand the question, look up the right product specs from your catalogue, check inventory availability, draft a response in the right tone, and flag it for human review before sending, that is an agent task. The path is not the same every time. The agent needs to reason about what to do.
Here's a practical test. Ask yourself: "Can I draw this as a flowchart with fixed branches?" If yes, it's a workflow. Use traditional automation. If the answer is "the branches depend on what the AI figures out," then you probably need an agent.
For many mid-market companies, the honest answer is that 80% of automation needs are workflows and 20% are genuinely agentic. The expensive mistake is treating the 80% as if it needs an agent framework. The smart move is to automate the workflows first (cheap, fast, reliable), then layer agents on top for the parts that genuinely need judgment.
Workflows (use traditional automation): invoice processing with fixed rules, CRM data entry from structured forms, scheduled report generation, file routing based on known categories, notification chains.
Agent territory (consider an AI agent): responding to varied customer inquiries across channels, summarising and extracting insights from unstructured documents, triaging support tickets based on content and urgency, generating personalised proposals or quotes from complex requirements, monitoring data anomalies and recommending actions.
Hybrid (the most common real-world pattern): a traditional workflow handles the predictable backbone, and an agent handles one fuzzy step within it. For example, an invoice arrives (workflow trigger), the agent extracts and interprets the line items from an unstructured PDF (agent step), the extracted data gets validated against a purchase order (deterministic check), and a human approves or flags exceptions (approval gate).
That hybrid pattern is what most lean IT teams should be targeting. It is realistic. It is maintainable. And it does not require your team to become AI infrastructure engineers.
The Main Types of Frameworks (And Which Ones Matter for You)
The AI agent framework landscape has exploded. There are dozens of options. But for a lean IT team, the decision is simpler than the market makes it look. The frameworks that matter fall into three buckets:
| Framework category | Best fit | Operational burden | Buyer default |
|---|---|---|---|
| LangGraph-style orchestration | Known workflows with state, branching, approvals, and audit | Medium: code, state design, testing, observability | Best default for governed business automation |
| CrewAI-style multi-agent teams | Role-based research, drafting, review, and analyst-style collaboration | Medium: easier abstraction, but less precise control | Useful when the task maps naturally to roles |
| Vendor-native frameworks | Teams already committed to Microsoft, Google, OpenAI, or another cloud ecosystem | Lower at first, higher lock-in risk later | Practical when ecosystem fit matters more than portability |
| OpenClaw-style operator runtime | Bounded autonomous work inside an isolated environment | Higher: sandboxing, runtime operations, cost controls, audit | Strong only when the agent truly needs autonomy |
| Normal automation | Fixed reports, notifications, record updates, scheduled tasks | Low | Better than an agent when the process is predictable |
Low-Level Orchestration: LangGraph
LangGraph is the most mature framework for building stateful, controlled agent workflows. Think of it as a system where you draw a graph of steps: "first do this, then check this, then either do A or B depending on the result." The framework executes it reliably, remembers where it was if something breaks, and lets humans intervene at any point.
Why it matters for your company: LangGraph gives you explicit control. Nothing happens that you didn't define. Every step is auditable. If the agent needs human approval before sending a customer response or modifying a record, you build that approval gate directly into the graph. For regulated industries, for financial processes, for anything where "the AI did something unexpected" is unacceptable, LangGraph is the strongest choice.
The trade-off: You need someone who can write Python and think in terms of workflows and state machines. Your analyst might be able to learn this, but your sysadmin probably can't pick it up in a weekend. It's not drag-and-drop. It's code. But it's well-documented code with a growing ecosystem of examples.
Real-world adoption: Companies like Klarna, Elastic, and Replit have deployed LangGraph in production, which is a meaningful maturity signal.
Multi-Agent Teams: CrewAI
CrewAI takes a different approach. Instead of drawing a graph of steps, you define "agents" with roles: a researcher, a writer, a reviewer. Then you let them collaborate on a task. It also has a more controlled mode called "Flows" for when you need explicit sequencing.
Why it matters for your company: CrewAI's abstraction is easier to reason about for non-engineers. "I need a research agent that gathers competitive pricing and a report agent that formats it" is closer to how business people think about delegation. The commercial platform also offers deployment options including on-premise and private cloud, which matters for data governance.
The trade-off: The higher-level abstraction means less precise control over exactly what happens in complex scenarios. The community debates whether CrewAI's multi-agent coordination adds overhead that simpler single-agent designs would avoid. For straightforward tasks, it can feel like you're over-engineering.
Real-world adoption: PwC, IBM, and AWS are among the organisations that have publicly referenced CrewAI usage.
Vendor-Native Frameworks: OpenAI Agents SDK, Google ADK, Microsoft Agent Framework
Each of the major model providers now offers their own agent framework. OpenAI has the Agents SDK with built-in sandbox execution, tool support, and MCP integration. Google has ADK (Agent Development Kit), which grows from simple agents to multi-agent systems and integrates into the Gemini Enterprise Agent Platform. Microsoft's Agent Framework reached version 1.0 in April 2026 and supports multiple model providers plus A2A/MCP interoperability.
Why they matter for your company: If you're already deeply invested in one cloud ecosystem, such as Microsoft 365 and Azure, Google Workspace and GCP, or heavy OpenAI API usage, the vendor-native framework reduces integration friction. You're already authenticated, your data is already there, and the framework is designed to work with the tools you have.
The trade-off: Lock-in. Building on OpenAI's Agents SDK ties you to OpenAI. Building on Google's ADK steers you toward Gemini and GCP. That's fine if you're committed to that ecosystem. It's a problem if you want flexibility to switch models when pricing or capabilities shift.
What About AutoGen, OpenClaw, and Others?
AutoGen was historically important but is now in maintenance mode. Microsoft's own strategic path is the newer Agent Framework. Don't start a new project on AutoGen in 2026.
OpenClaw is powerful but positioned differently. It is a personal AI assistant and self-hosted multi-channel gateway. It is excellent for operator-style automation and coding-agent access, but it is not a multi-tenant enterprise orchestration platform. If you're interested in deploying a sandboxed autonomous assistant for individual power users or developers, it is worth evaluating. If you're building shared business-process automation for your company, it is a layer that needs isolation and guardrails, not the default platform. We've written in more depth about this in our LangGraph vs OpenClaw comparison.
Agency Swarm, Autogen successor projects, Semantic Kernel: these exist but are either smaller in community, more niche in target, or still maturing. For a lean IT team, the pragmatic choice is to stick with the frameworks that have visible production adoption and active documentation.
MCP and A2A: What They Are and Why You Should Care (But Not Panic)
You'll hear these two acronyms a lot. Here's what they mean in practical terms.
MCP (Model Context Protocol) is a standard that lets your AI agent connect to external tools and data sources in a standardised way. Instead of writing custom integration code for every tool your agent needs to access, such as your CRM, your ERP, your email system, or your database, you use an MCP "server" that provides a standard interface. The agent knows how to speak MCP, the tool has an MCP server, and they connect.
Think of it like USB for AI agents. Before USB, every device needed its own cable and driver. MCP is trying to be the universal connector.
Where it stands today: MCP has strong momentum. It is under the Linux Foundation, has a growing ecosystem of pre-built servers, and is supported by most major frameworks. But the authentication, authorisation, and multi-user parts are still being hardened. If you have many users who all need the agent to access their own data without seeing each other's, the MCP story is not yet plug-and-play for that scenario.
A2A (Agent-to-Agent protocol) is the standard for agents talking to other agents. It is younger than MCP, but backed by Google and Microsoft, with more than 50 launch partners. For most lean IT teams, A2A is a strategic bet to track, not something you need to implement today. It matters more when you have multiple agent systems that need to coordinate. For example, your internal operations agent may eventually need to talk to your supplier's procurement agent. That is a real future scenario, but it is not this quarter's project.
What you should actually do today: If you're evaluating frameworks, confirm they support MCP. That is your insurance policy against having to rewrite tool integrations later. Don't wait for A2A to be production-ready before starting your first agent project. By the time you need it, it will probably be more mature.
Self-Hosted vs API: The Real Calculation
This debate comes up in every evaluation, and the community discussion is intense. Here's how to think about it when your team has limited operational capacity.
| Deployment model | What it means | Best for | Main risk for lean IT teams |
|---|---|---|---|
| Managed API | Use OpenAI, Anthropic, Google, or another hosted model provider | Most first projects, complex reasoning, document work, customer response drafts | Variable cost, vendor dependency, data-handling review |
| Self-hosted model | Run open models such as Llama, Mistral, or Qwen on your own infrastructure | Strict data locality, very high-volume narrow tasks, sovereignty requirements | GPU operations, model serving, monitoring, patching, staffing |
| Hybrid | Use managed frontier models for hard reasoning and smaller local models for narrow tasks | Mature teams with measured needs in both categories | Two operating models instead of one |
API-first (OpenAI, Anthropic, Google managed) means you send requests to a cloud service and pay per use. You don't manage infrastructure. The models are always the latest version. The trade-off is that your data travels to a third party, costs are variable and can spike, and you depend on the provider's uptime and pricing decisions.
Self-hosted (Llama, Mistral, Qwen on your own infrastructure) means you run the model on your own servers or cloud VMs. You have full control over data because nothing leaves your environment. The trade-off is significant: you need GPU infrastructure, someone who can manage model serving, and a clear reason to accept the operational burden. Open models are capable for many tasks but still lag behind frontier models on complex reasoning, nuanced writing, and broad autonomous workflows.
For lean IT teams, the honest recommendation is this: Start with API-first. Use OpenAI, Anthropic, or Google's managed services. The privacy controls on all three commercial providers now explicitly state that business data is not used for training by default, and all offer data residency and retention controls. That's good enough for most mid-market compliance needs.
Self-hosting makes sense in three specific scenarios: you're in a heavily regulated industry where data cannot leave your premises under any circumstances (defence, certain healthcare, certain financial services); you have a single narrow task that runs at very high volume (thousands of calls per hour) where API costs exceed infrastructure costs; or data sovereignty is a legal requirement and the API providers' contractual terms don't satisfy your legal counsel.
If none of those apply, the cost and maintenance burden of self-hosting will overwhelm a lean team. A sysadmin who's already managing servers, network, and helpdesk tickets does not need to also become a GPU infrastructure and model-serving specialist.
The pragmatic middle ground is hybrid: use API-first services for the tasks that need frontier reasoning, such as complex document understanding, nuanced customer responses, and sophisticated data analysis. Run a smaller open model locally only for narrow, high-volume, or privacy-sensitive tasks, such as data classification or structured extraction from internal documents. Add the self-hosted piece when you have a proven, measured need, not as a default architecture.
What Lean IT Teams Are Actually Running in Production
The gap between what the AI industry markets and what lean IT teams can actually deploy is enormous. Here's what's real today:
| Maturity level | Practical examples | How to run it safely |
|---|---|---|
| Deployed and working | Coding assistance with human review; internal document search; support-ticket triage; structured extraction from invoices, contracts, or forms; report generation from database queries | Keep scope narrow, log the work, and keep humans in review loops |
| Emerging but supervised | Email response drafting; meeting summaries and action items; sales proposal generation; procurement matching against catalogues | Require approval before send, purchase, customer contact, or record modification |
| Still experimental for most lean teams | Fully autonomous customer-facing agents; broad-scope assistants with access to many production systems; multi-agent delegation across business functions | Avoid until observability, approval, rollback, and ownership are mature |
The pattern is clear: the companies getting real value from AI agents are the ones using them in supervised, bounded, single-workflow deployments. Not the ones trying to build an autonomous general-purpose business brain.
This matches what the major providers are seeing. Anthropic's own 2026 analysis estimates that developers can "fully delegate" only 0-20% of tasks, with the rest requiring human collaboration. The customer stories from OpenAI, Google, and Anthropic all describe targeted, bounded deployments, not autonomous empires.
How to Evaluate a Framework When You Have a Lean IT Team
Here's a practical evaluation checklist for companies with limited engineering resources:
| Evaluation question | Why it matters | What good looks like |
|---|---|---|
| Can your analyst learn it in two weeks? | A framework that requires deep platform engineering will stall after the pilot | A technical analyst can understand the workflow, state, logs, and failure modes |
| Does it have a managed deployment option? | Your sysadmin should not become an agent-runtime SRE by accident | Hosting, scaling, persistence, and tracing are handled or well documented |
| Can a human approve every consequential action? | Human-in-the-loop is non-negotiable for lean IT teams | Approval gates are easy to add before external sends, record changes, purchases, or customer impact |
| Is the state durable? | Business workflows often span minutes, hours, or days | The system can pause, resume, retry, and recover without losing context |
| How does it handle failure? | APIs time out, tools fail, and models make bad assumptions | Failures are caught, retried where appropriate, and escalated to a human when needed |
| Can you observe what it is doing? | Debugging an agent without traces is miserable | You can inspect prompts, tool calls, state changes, approvals, errors, and outputs |
| Does it support MCP? | Tool integrations should not become throwaway custom code | MCP support exists or the integration layer is abstracted enough to migrate later |
A Decision Matrix for Your First Project
Don't try to boil the ocean. Pick one workflow. Here's how to choose it:
| Project type | What to do | Good examples |
|---|---|---|
| High value, low risk | Start here | Customer inquiry triage, document extraction and summarisation, internal knowledge search across scattered systems |
| High value, high risk | Second priority, after the first project teaches you the failure modes | Customer-facing workflows, financial workflows, compliance workflows, production record changes |
| Low value, low risk | Use for learning, but do not over-invest | Internal helpers, personal productivity tools, low-impact experiments |
| Low value, high risk | Avoid | Anything with weak ROI and customer, finance, compliance, or production-system risk |
For your first project, the sweet spot is almost always internal operations, human-reviewed output, one data source, one action. Get that right. Learn how the framework behaves. Understand the failure modes. Then expand.
How to Start Without Getting Locked In
The most practical architecture for a lean IT team follows three principles:
Keep the model layer swappable. Use a framework that supports multiple model providers, or abstract the model calls behind a simple interface. Today you might use Claude for its quality. Next quarter, GPT-5 might be better for your use case. Don't marry the first model you test.
Use MCP for tool integrations. Even if the MCP ecosystem is still maturing, building your integrations against MCP servers means you can swap frameworks without rewriting every data connection.
Start with one workflow, one framework, one human in the loop. Resist the temptation to evaluate five frameworks in parallel. Pick the one that best matches your first project's requirements, build it, ship it, learn from it. If it doesn't work, the sunk cost of one bounded project is manageable. The sunk cost of six months evaluating frameworks with nothing in production is not.
| Architecture principle | Practical meaning |
|---|---|
| Keep the model layer swappable | Do not let the business process depend on one model vendor forever |
| Use MCP for tool integrations where it fits | Keep tool access portable enough to survive framework changes |
| Start with one workflow | Learn from a bounded production system before expanding the surface area |
| Keep one human approval loop | Make the first deployment useful without pretending it is fully autonomous |
| Measure the operating cost | Track approval rate, correction rate, latency, token cost, and time saved |
The honest truth is that for most companies with a small IT team, the best first move is to work with a consultancy that has already shipped this kind of system. Not because your team cannot learn. They can. The reason is that the difference between a well-architected agent deployment and a poorly architected one is often invisible until something goes wrong in production.
That is the real selection criterion. Choose the framework, architecture, and partner that your team can actually operate when the demo is over.